






This trick gives a way to break the traditional rendering cycle and interact
with PRMan while it is rendering. Before going into the details, the above movie shows a demo of some aspects of the trick. It shows PRMan rendering as normal, then the camera being moved, and the light and material tweaked.
The trick consists of a viewer program (like an interactive form of It) which
handles the display and sends requests down a network socket to a ray server DSO running in PRMan. The ray server in turn takes those requests, traces the required rays, and sends the results back to the viewer display.
This arrangement is similar to the days when PRMan used BMRT to trace rays,
before it had native support for ray tracing.
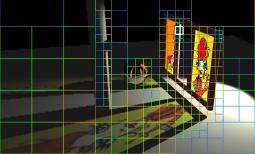
The main role of the viewer is to handle the camera position and the progressive
refinement of the image.
This movie shows the viewer refining a scene. It maintains a pyramid of images
and a list of buckets that still need to be rendered, continuously sorting them by a contrast metric. In the movie the progress mode displays these buckets with a temperature scale - when one bucket finishes, the next reddest one is started.
The viewer uses OpenGL to render the multi-resolution images.
What do we mean by asking PRMan to trace some rays for us? Obviously PRMan
usually operates by using your shaders and DSOs as and when it needs to render the final image, and there is no DSO API to trace whatever you want in the scene.
The core of the trick is inverting this relationship and taking control of PRMan.
We stick a piece of geometry in front of the lens with a very simple shader (DSO calls in bold):
surface hb_interact_lens()
{
point pos;
vector dir;
color col;
while(1)
{
pos=hb_interact_get_origin();
dir=hb_interact_get_direction();
col=trace(pos,dir);
hb_interact_put_colour(col);
}
}
All it does is keep asking the DSO for a position and direction, traces the ray,
and sends the result back to the DSO. It never finishes - once this is running, PRMan will trace whatever the DSO wants it to.
Since this is effectively a single threaded program, we don't want PRMan to do
any SIMD processing. So, the easiest way to do this is just to put a huge point in front of the camera - since that will only be shaded at one location, rather than a standard grid.
The DSO handles the other end of the socket to the viewer.
struct Packet
{
float origin[3];
float x[3];
float y[3];
float z[3];
float lx, ly;
float hx, hy;
int sx, sy;
int samples;
};
It receives simple packets with enough information in them to describe a camera
and section of the image plane.
Once all the required pixels have been returned to the DSO, it sends them back to
the viewer as a small image.

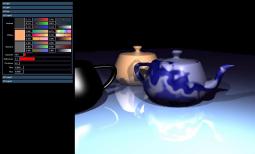

To interact with the camera you simply adjust the matrix in the packets sent to
the DSO. I first realised this trick had potential when I noticed I could spin the teapot in real time.
We also want to be able to interact with the materials. This can be done by
changing the material shader to pick up the interaction variables from the DSO.
surface test_material(uniform float interact_offset=1)
{
uniform color ambient=hb_interact_variable(interact_offset+0);
uniform color diffuse=hb_interact_variable(interact_offset+3);
uniform color specular=hb_interact_variable(interact_offset+6);
This can be done manually, or automatically - especially if they are generated by
some shading tree system. In the current implementation these calls pick up variables from a linear array of floats maintained via the socket, and
interact_index specifies where in the array the values come from. In
these test scenes, I just laid them out manually.
In these movies, the variables are presented in a simple dialogue, but in an
integrated implementation they would be connected to the values in the host application.
Unfortunately we can only change variables - we can't switch the shaders or
rewire them.
Tweaking lights is very similar to materials.
point from=hb_interact_variable(interact_offset);
The light positions are retrieved from the DSO and PRMan's tracing does the rest.
Shadow maps could still be used for static lights - variables such as distribution could be changed, but moving the light would produce incorrect results.
Again, in the movies, the lights are adjusted via a dialogue - obviously some
kind of manipulator would be preferable.
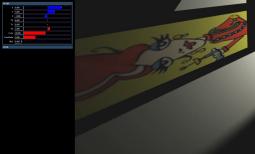


Lots of shaders sample something else in the scene - like lighting or occlusion.
In this case, we want high speed feedback initially, followed by high quality results eventually. To achieve this, the DSO exposes the level of the bucket being processed to the shader so it can decide how many samples to use for the bucket.
uniform float samples=hb_interact_level()+1;
samples=4+samples*samples*samples;
The movies show adjusting the blur on a light, varying the maxdist on an
occlusion shader, and racking focus on a scene with limited depth of field.
In the case of occlusion, PRMan tries hard to speed up the rendering by using a
cache for occlusion queries, so they are often calculated by interpolating nearby past requests. The interactive shader has to disable this so later requests aren't calculated from previous requests with old parameter values.
A fairly simple extension of this trick is to use multiple hosts to spread the
rendering load. In fact, with dual CPU hosts, we need to run two copies of PRMan to take advantage of both processors - as it will not be able to parallelise our single lens primitive.
As with any interactive application running over a network, you quickly get into
limitations such as bandwidth and latency. Ignoring those details, each host behaves just like the single host in that it loads the complete scene and listens for trace requests.

It is then up to the viewer to hand out the buckets that need to be rendered to
the list of hosts that are waiting. This movie shows the view controlling four hosts, with the thick squares showing buckets in progress, coloured by host.
Once this was working I wanted to see how far the system could be pushed. I
managed to get access to 140 CPUs on a renderfarm, and I tried connecting them all to a single viewer. At this scale network congestion issues dropped the performance way below linear scaling, but it still performed well.



The tank movie shows the speed of refining out the noise. The dragon was the
largest polygonal model (870K faces) that would fit into each 2GB host (twice - once per process) without swapping.
The volumetric lighting scene was quickly assembled to stress test the setup. The
shader is really far from optimal, but it is still possible to interact with it.
There are some problems with derivatives. They centre around the fact that at the
top level, the geometry we are shading is a single point and so has no derivatives. There were some hints that certain gather calls could trace a ray with derivatives even from a point, but there were odd noise issues.
I ended up having to change the lens geometry from the point to a grid, so that
the derivatives on the grid would flow through to the rays traced from it. This complicates the shader and DSO details as they have to keep track of all the rays on the grid. The following movie shows the calculatenormal call working on the killeroo.

There was also a problem that this technique only seemed to work with PRMan 12.0.
Clearly there are some issues I need to discuss with Pixar support, and I'll udpate this once I work out where the problems are.
There are several significant limitations of this trick. The main one is that we
are raytracing everything and so the whole scene must be in memory. I found I could get almost a million polygon model into a 1GB machine before it started swapping. All the techniques PRMan uses for caching and discarding tesselated geometry will get confused because the viewer keeps firing rays in fairly arbitrary directions. It might be possible to bias the bucket selection method towards buckets that are near the last one, but I expect the performance will still be non-interactive once the scene doesn't exist entirely in memory.
Also, by the time we are in control, all geometry has been tesselated and
displaced, so there is no way to interact with geometry placement or displacements. In theory you could restart a new frame without the user noticing, but it would still take a noticable amount of time to re-tesselate the scene.
There's no reason that instead of a single variable lookup in a material, you
couldn't lookup from a texture stored in shared memory. This would allow you to be painting a texture in one application, and have PRMan update just the changed pixels in a fully shaded view. I will look into this soon and will update this page with the results.
Also, in all these demos, I'm being really conservative by refreshing the whole
display whenever anything changes. It would be a simple extension to update, for example, only the parts affected by a changing light and leave all the unaffected parts at high resolution.
It would also be possible to apply progressive refinement in a rendermapping (or
other non-camera) system, by sending a complete (origin, direction) pair per ray from the viewer.
In the multiple hosts case, it would be interesting to let the viewer evaluate
the relative speeds and latencies of the hosts it has access to. It could send several identical bucket requests out and measure all the response times.
Finally the GPU spends most of its time idle. It could handle tone mapping,
displaying glows around hot pixels, or many other useful image processing functions. It could also do lots of things with arbitrary outputs if they were sent back from the viewer too.